The setup
I rebuilt the ns-3 backend (./ns3 configure --enable-mpi && ./ns3 build
AstraSimNetwork) and ran a matched 8-node slice: a one-hop switch fabric vs
a ring (= 1-D torus), both pinned to 400 Gbps / 500 ns links so the only
difference is fabric structure, driving the same Chakra workloads through
ns-3’s packet-level RDMA model across 16 KiB → 16 MiB.
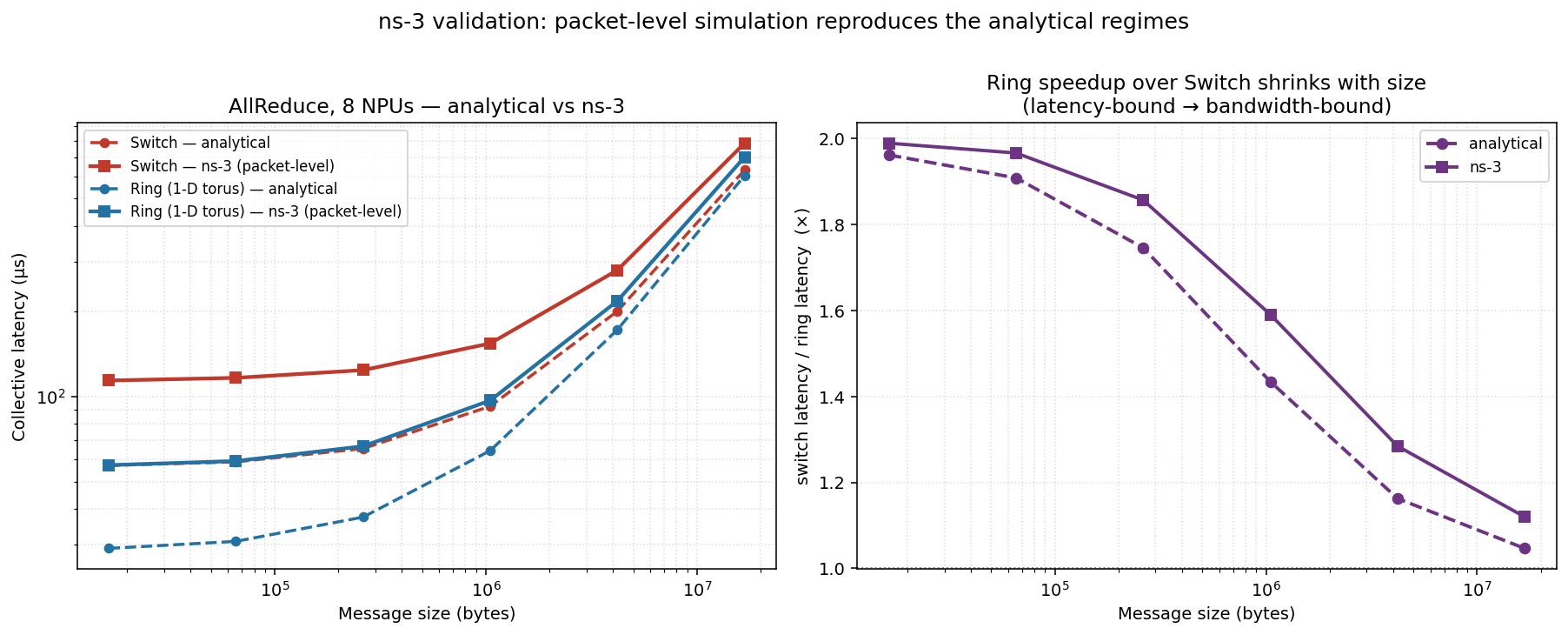
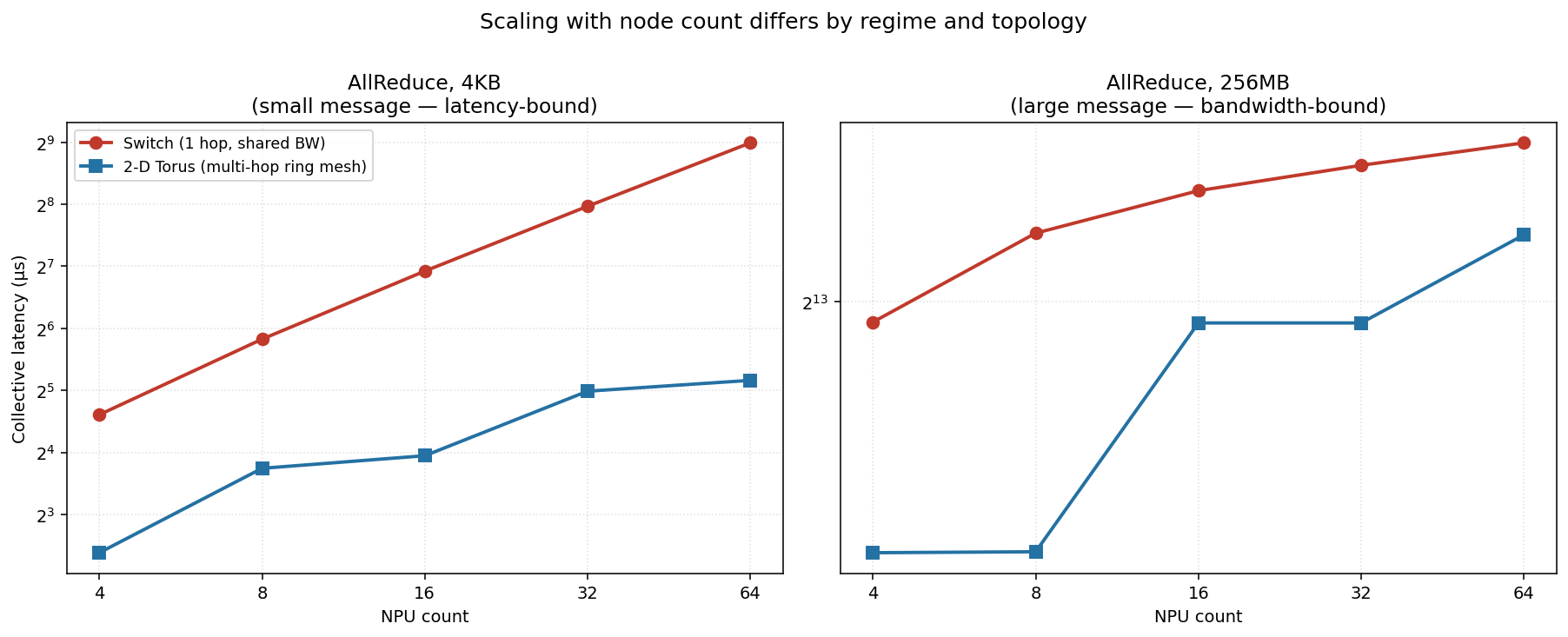
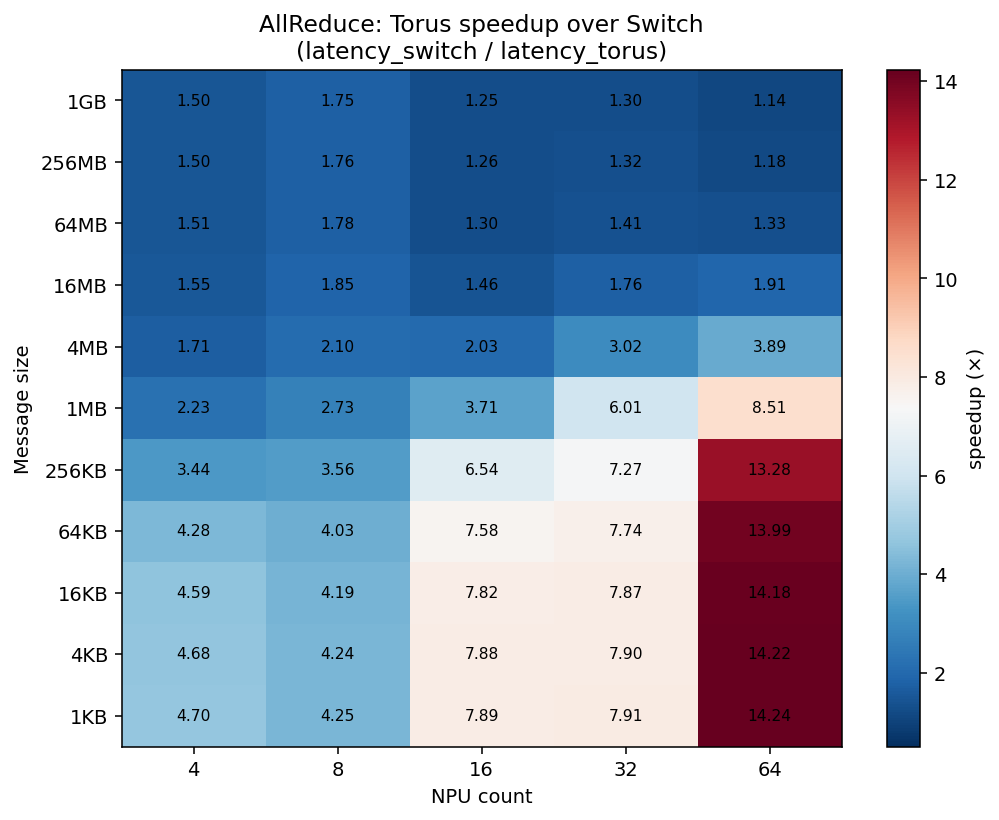
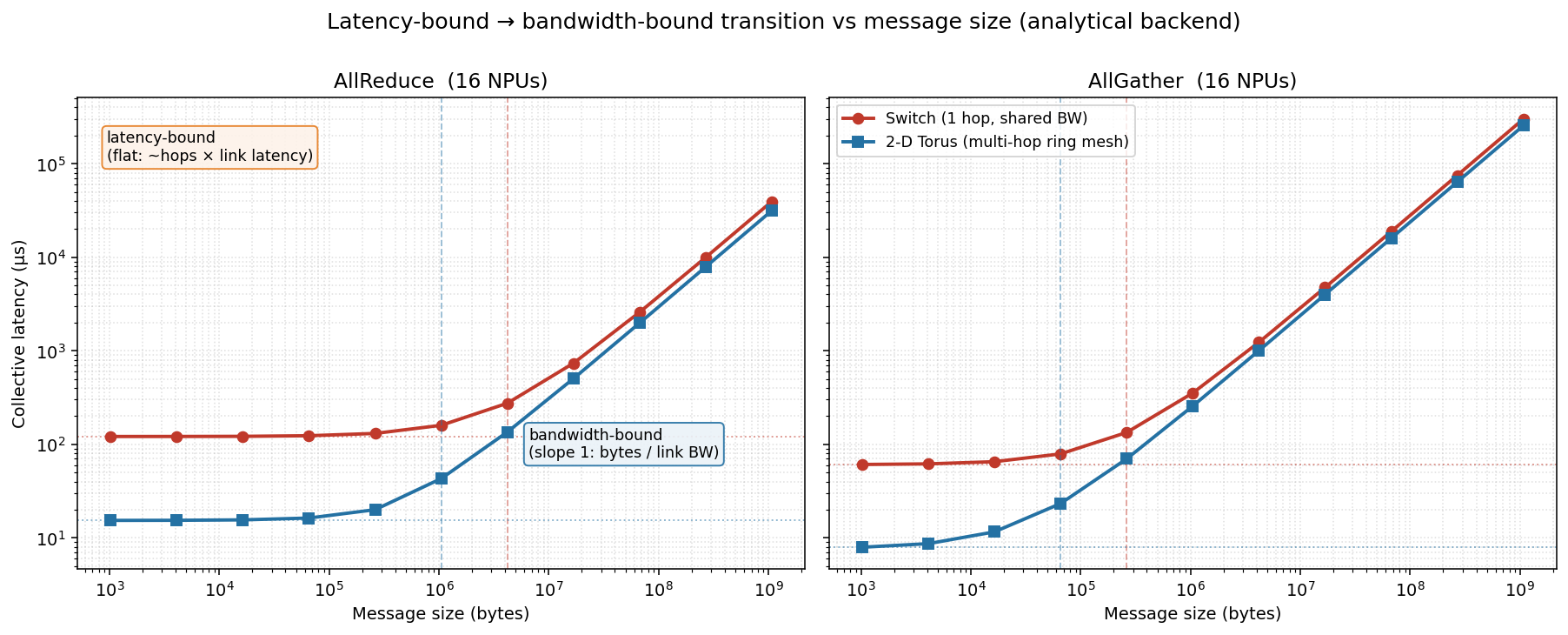
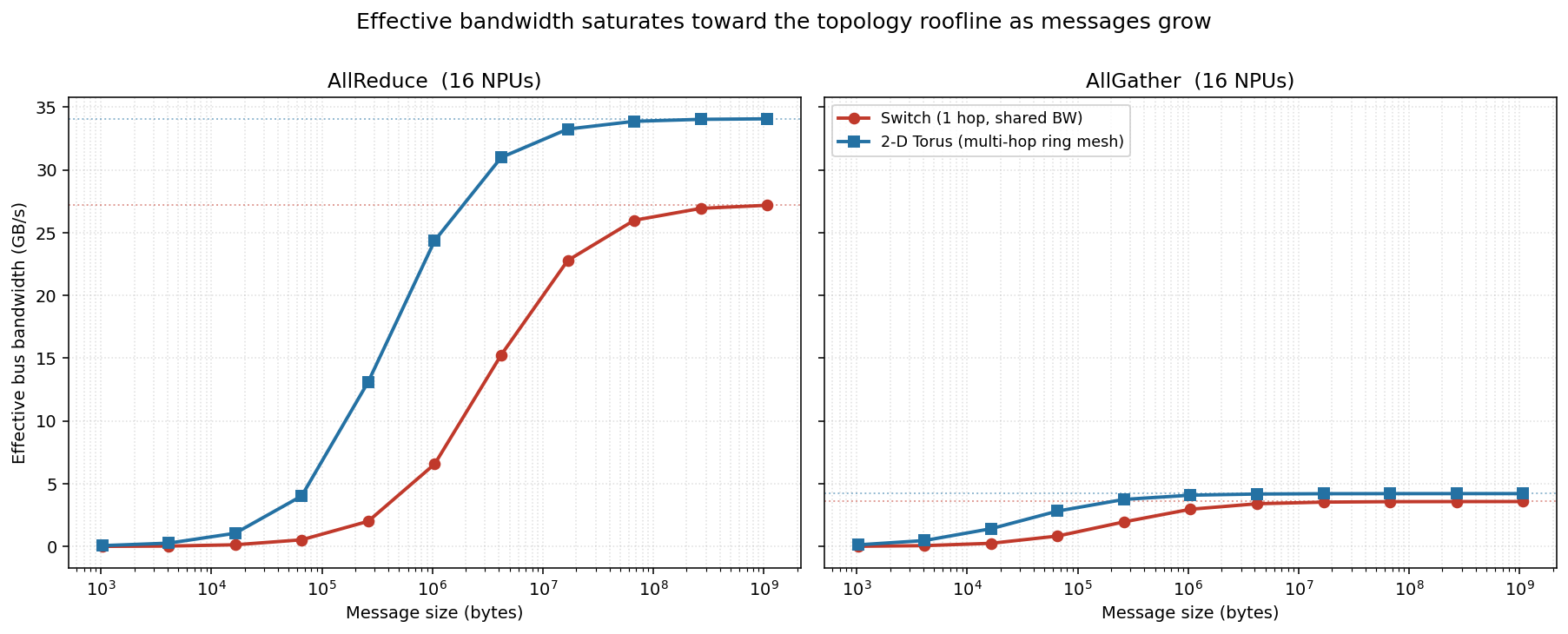
The regimes survive
ns-3 sits above the analytical model everywhere (left panel) — it pays for packet headers and the congestion-control ramp the idealized model ignores, and that overhead is relatively larger for small messages — but the shape is the same: a flat latency-bound floor, a bandwidth-bound ramp, and ring consistently below switch.
The clincher is the right panel: the ring-over-switch speedup shrinks from ~2× (latency-bound) toward ~1.1× (bandwidth-bound) in both backends, tracking each other closely.
| Size | switch (ns-3) | ring (ns-3) | speedup — ns-3 / analytical |
|---|---|---|---|
| 16 KiB | 113.9 µs | 57.3 µs | 1.99× / 1.96× (latency-bound) |
| 16 MiB | 784.6 µs | 700.7 µs | 1.12× / 1.05× (bandwidth-bound) |
A second, more detailed simulator independently reproduces the central finding — topology matters most when you’re latency-bound — which is exactly the confidence cross-backend validation is supposed to buy.
What I’d model next
- 3-D torus and fat-tree at 256–1024 NPUs, where diameter differences widen.
- Algorithm × topology: halving-doubling and direct AllReduce, not just ring — the latency floor is set by the algorithm’s step count, so the regime map shifts.
- ns-3 congestion at scale: where does PFC / back-pressure make the analytical model optimistic?
Code, configs, and all five figures: github.com/kredd2506/Astro.
]]>