The previous post fixed the node count and swept message size. Here I do the opposite — fix the message size and sweep the node count — because that’s where the two regimes diverge most, and where topology choice either pays off enormously or barely matters.
Scaling with node count depends on the regime
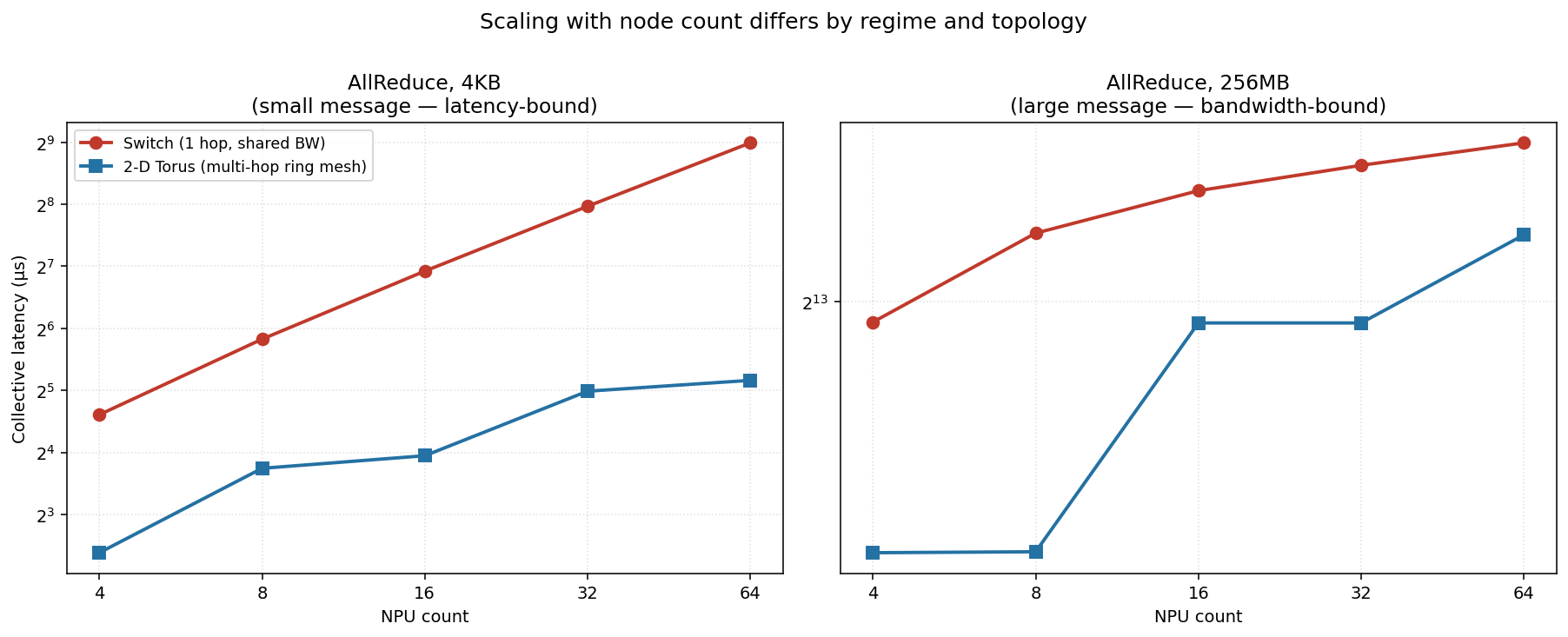
This is the part that bites in practice. Latency-bound (left, 4 KB): the
switch’s latency grows almost linearly with N — 24 → 57 → 121 → 251 → 509 µs
from 4 to 64 NPUs — because ring-on-switch executes N−1 sequential hops. The
torus grows far more slowly (steps scale with the longest dimension, ~√N).
Bandwidth-bound (right, 256 MB): both fabrics flatten out — adding nodes
barely changes time, because the per-node data volume of a ring collective is
nearly independent of N — and the gap narrows to a constant factor.
One picture: when does topology matter?
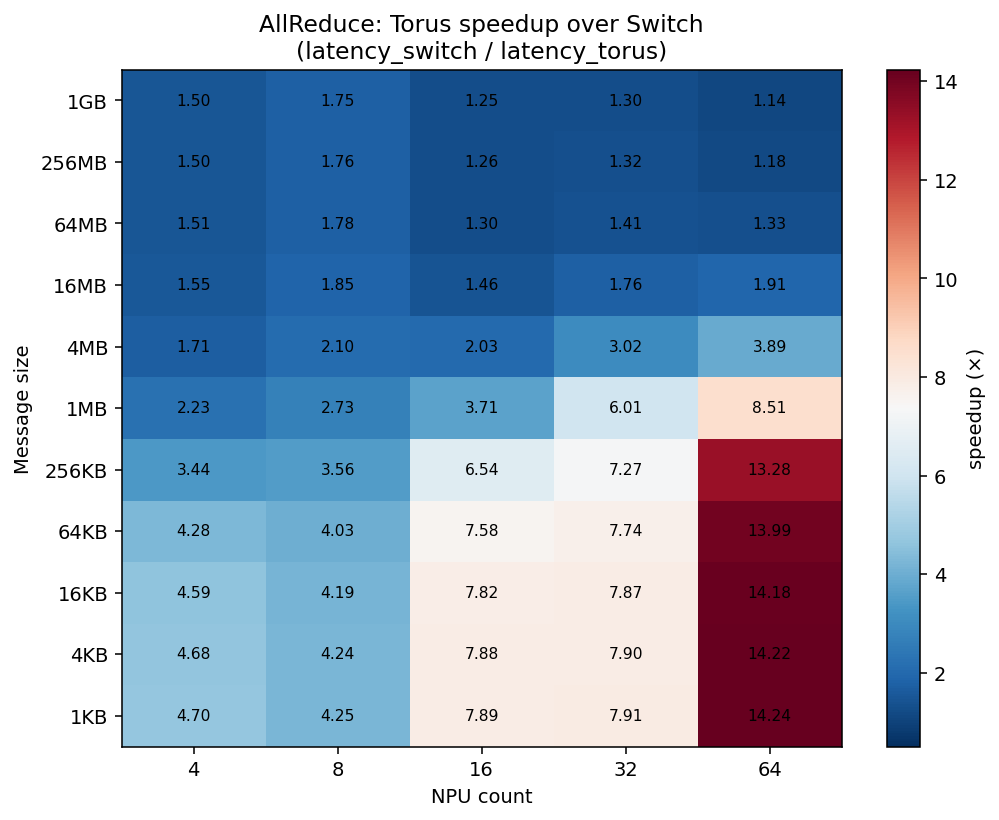
Torus speedup over switch for AllReduce across every (size, node) cell. The story is a gradient:
- Top-left (large messages): ~1.1–1.8×. Bandwidth-bound — topology is a second-order effect; you’re paying for bytes either way.
- Bottom-right (small messages, many nodes): up to 14.2×. Latency-bound
at scale — topology is everything, because hop count is what you’re paying
for, and that’s exactly where torus and switch differ most (
N−1sequential switch hops vs ~2(√N−1)on the torus).
The takeaway for system design: if your collectives are small and frequent (latency-bound — small gradients, frequent syncs, large clusters), fabric topology dominates and a low-diameter mesh pays off enormously. If they’re large and infrequent (bandwidth-bound — big tensors), you are buying raw link bandwidth and the topology choice matters far less.
The analytical backend is an idealized link model, though. The final post checks these regimes against ASTRA-sim’s ns-3 packet-level backend.